
Do Large Language Models have a "Reasoning Gap"?
“True reasoning” vs “memorisation”
The recent release of the functional MATH() dataset came with a paper and a twitter thread that headlined with an impressive sounding claim:
“More than 50% of the reported reasoning abilities of LLMs might not be true reasoning.”
The thread goes on to explain although many popular Large Language Models (LLMs) seem to be able to solve complex math problems, those abilities get significantly reduced when you make superficial changes to those problems. These small changes are meant to affect the numerical answer without changing the underlying reasoning needed to solve the problem. The poor results on the modified problems suggests that LLMs aren’t learning general techniques, but instead have memorised specific solutions. The authors call this difference in ability a “reasoning gap”.
Since LLMs are trained on massive quantities of data extracted from the Internet this claim is entirely plausible. Math problems from test sets could appear anywhere online and leak into the training data. The reasoning capabilities of LLMs seem like a key forward step in AI development, so MATH() is addressing an important question. However, having looked at the data itself, I think there are some issues with the approach, and, for now we should take these results with a grain of salt.
MATH()
MATH() is a system for synthetically generating data, based on a static dataset called MATH. (As in the joke about the panda who eats, shoots and leaves, the extra punctuation makes the difference.) The original MATH dataset is a collection of maths problems with human-written solutions, including explanations of reasoning, intended for training and evaluating language models. To create MATH(), the authors wrote data generating code that used the static problems as templates. By replacing values in a MATH problem with random numbers, and then updating the resulting calculations, you can create endless new variations.
Although the MATH() data generation code is closed source, the authors have released three generated datasets (or snapshots) and the evaluation code, so you can replicate their experiments.
A Little Grading Experience
I am interested in the capabilities of LLMs, and after talking to a friend about this “reasoning gap”, we were both curious about whether an LLM could solve these math problems more generally. If LLMs fail to generalise, that means instead of learning how to solve a problem, they learn to recognise the exact question and short-cut to a memorised answer. I was curious to see if I pushed a model to learn longer and more detailed solutions, would it avoid the short-cut and learn the pattern. Getting an LLM to output intermediary steps can improve reasoning capabilities, so this seemed plausible.
My plan was to fine-tune an LLM using a small number of very detailed explanatory solutions and then test on MATH() data. I decided to target algebra problems, as I thought narrowing the focus would increase the impact and this was the area with largest reported “reasoning gap”. To this end, I wrote out 100 solutions to problems from the test/algebra directory in the December 2023 snapshot of MATH() data.
Fine Tuning Results
I experimented with GPT-3.5-turbo, fine tuning it with the 100 solutions that I had written. For comparison, I also fine tuned a GPT-3.5-turbo model on 100 MATH training data, (which contains concise explanatory reasoning). I used the MATH algebra test set (1187 problems) and the November 2023 MATH() snapshot algebra test set (516 problems) for evaluation.
I found that using the provided evaluation code from the fneval repo gave similar results for GPT-3 as reported in their paper. However, I notice some correct answers were not being accepted. The evaluation code seems to expect a solution with no other text. I redid my experiments, extracting the last mathematical expression from the model response, and got about a 30% increase in correct answers on both datasets.
I found that fine-tuning on the original MATH data gave big improvements on both datasets. There was an 87% increase and a 67% increase in correct answers on MATH and MATH() respectively. It is surprising that just 100 examples can have such a big impact. However, the model trained on the solutions I wrote did less well, showing a 19% increase of correct answers on MATH but a 7% decrease for MATH(). Fine-tuning actually made the model worse!
Following the tactic of the Grok-1 authors, I also tested out these models on a 2023 Hungarian high school maths exam. The exam contains 33 questions and must be scored manually, since some marks depend on intermediary steps. Since GPT-3.5-turbo was trained on data obtained by 2021, (and there’s no overlap between this exam and MATH), these questions should be entirely new to the models. I found that standard GPT-3.5-turbo got 40% exam points, and the instance fine-tuned on MATH data got 49%. It seems, fine-tuning can help generalise maths reasoning. However, the instance fine-tuned on my own data got 30%, again showing that fine-tuning on my data decreases maths ability.
Looking at the outputs for the model fine-tuned on my data, I did see that it was writing longer responses with smaller steps as I had hoped. (In fact, its responses were on average over twice as long as the other fine-tuned model.) In particular, my solutions included a lot of detail that would help with long arithmetic, and the model showed attempts to copy this behaviour. This was especially evident while grading the Hungarian math exam, where I saw the model often tried to give a long detailed answer, but at some point it would go in the wrong direction and not recover.
One explanation could be that long math solutions are less common in pre-training data, so my fine-tuning pushed the model into unfamiliar territory where it performed worse. Alternatively, maybe longer solutions are just harder in general for LLMs, e.g. they give more opportunities for the model to make a mistake, hallucinate or otherwise go off track. For example, take this MATH problem:

This attempted solution fails at the last step when trying to add 441 and 784. We see the model correctly applying a complex solution method, but failing due to an arithmetic error. (In contrast, the model trained on MATH data solves the problem in two lines, doing most arithmetic in one step.)
These results suggest LLMs can learn larger patterns of reasoning, but consistency over long outputs can become a hurdle.
I think, for reasons I discuss below, MATH() problems invite longer solutions, making them inherently harder for language models to solve. So, for now, I don’t consider MATH() data helpful for answering my questions about LLM capabilities.
MATH() Problems
The experience of writing out solutions to MATH() algebra problems was much harder than I expected. I saw several issues that I thought made some problems unfairly difficult. I went through the first 110 problems by directory listing (only writing solutions for 100). Out of these, I found 23 that I thought were unsuitable for training and evaluating LLMs.
Bad MATH()
There were 9 problems with clear errors where either the given solution was incorrect or the question was ambiguous, meaning that a correct answer could be evaluated as wrong. There were 3 further problems where their solutions were incorrect because of a common LaTeX mistake in the problem statement (where curly brackets are missing from an exponent). While this is a minor typo that an experienced human could spot, it’s not clear a language model should be expected to automatically correct for it.
There were also 5 problems that I considered impractical to do by hand, and 7 that involved overly long calculations. For example, some problems had solutions that were over 14 digits long, some required factorising large numbers, others required onerous long divisions, etc. I resorted to using a python script to write out detailed long arithmetic.
Compare some of these MATH() problems with their MATH counterparts:



It seems some problems that require a certain level of reasoning get generalised into problems that require the same level of reasoning and long arithmetic consistency.
For a complete breakdown of each of these problems, see my other blog post.
Difficult MATH()
Apart from the obvious issues discussed above, in my observation, it seems like the random numbers used in MATH() are generally bigger or harder to deal with than their MATH originals. For example, take these level 1 problems from the two datasets:
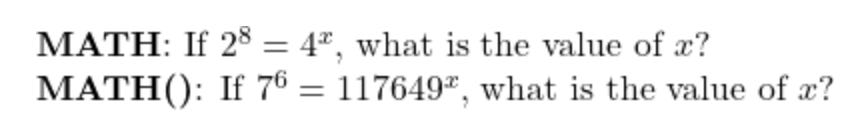
The MATH problem is quite easy if you know your times table, 2 * 2 = 4, and therefore 8 = 2x and x = 4. To apply a similar logic to the MATH() problem, you must know 117649 is 7 to the power 6.
Or, for example, there are these problems:
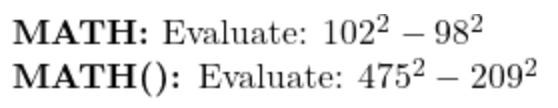
The model I fine-tuned on MATH algebra data was able to solve the original but failed to solve the generalised version. To solve this problem, you apply the difference of squares formula:
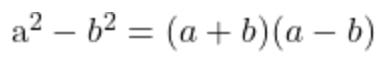
For the first problem, (102 + 98) (102 - 98) = 200 * 4 = 800, which is a much simpler calculation than the second problem requires.
I tested the MATH fine-tuned model on some randomly generated similar questions, using two different methods:

In the first method a and b are just random 3 digit numbers, but in the second, (a - b) is a random 2 digit even number and (a + b) is 100 times another random 2 digit even number. I tested on 100 questions each and for the first method, the model got 18 correct answers, but for the second, it got 54 correct. Unless there is a web page listing thousands of examples of this exact problem, it seems that the model is capable of applying the difference of squares formula more generally when the required calculations are easier.
The MATH algebra questions are full of situations where knowing a power, logarithm, factorisation or common arithmetic result makes the question much easier. This makes sense, as these questions were written, and their difficulty levels determined, with an assumed level of common maths knowledge in mind. Language models seem to copy human reasoning, and common knowledge for humans is likely to occur frequently in pre-training data and be strongly memorised by LLMs. So, I would expect these MATH() problems to be harder than their originals even for an LLM applying human-like reasoning.
Bias
The “reasoning gap” comes from comparing performance of LLMs on the MATH dataset versus the MATH() snapshot. For this to be meaningful, it should be a fair comparison. Otherwise, the “reasoning gap” would be biased towards an inflated result.
The MATH() paper doesn’t discuss potential generation errors. It does mention overly large random numbers as a threat to validity in Section 6, but claims this would be a rare occurrence. From my small sample of algebra data, I found 10% that were mathematically ambiguous or incorrect and a further 11.8% that I thought were unfairly hard. Plus, I saw a widespread increase in difficulty going from MATH to MATH(), where original problems relied on common knowledge not be available once generalised.
The sample size was small, and some of this analysis is subjective. However, the issues are frequent enough for me to be concerned about bias in the “reasoning gap” measurements.
Suggestions for MATH()
I was very interested in MATH() and the “reasoning gap” claim, and had hoped to explore ways to narrow that gap with targeted data focused on a specific problem area. Instead I got bogged down with problems with the data - a typical machine learning engineering experience.
In general, I think that MATH() is a significant effort that attempts to address an important issue, and I don’t doubt the reported “reasoning gap” is measuring some memorisation. However, some part of it could be down to unfair comparisons. In particular, I found that MATH() has noticeable bugs, which I think have to be addressed for this to be a useful metric.
Further, random number ranges seem to be too broad, giving generalisations that require different reasoning to the originals. This is a difficult issue to solve, as narrowing the range of available numbers increases the likelihood of memorisation.
Consider these questions from the two datasets:

To solve the MATH problems, a human can do one or two divisions and apply some common knowledge. In contrast, 6103515625 is 5 to the power of 14, taking many more steps to solve. To be fairer, we might seek problems that can be solved easily after one or two calculations. However, being within a step or two of human common knowledge may not escape language model memorisation. The requirements for a truly fair comparison could be model dependent and hard to determine.
My concrete suggestions would be the following:
Open source the MATH() generation code so it can be checked and fixed by interested parties. In the time it took me to write this blog post, I could have fixed a few bugs instead.
Test correctness of problem answers when they are generated.
Template the full MATH solutions, including the explanatory reasoning. If this isn’t possible, that’s a sign the generalised problem doesn’t require the same reasoning as the original and may need to be revised.
Experiment with different random number ranges for substitutions. See how the “reasoning gap” changes as problems are generalised with increasingly larger numbers - look for a temporary flattening where memorisation benefit tails off, but arithmetic is not a significant challenge. That could be a more reasonable “reasoning gap” measurement.
Alternative Approaches
Trying to get an LLM to accurately apply complex math solution patterns seems difficult. I have seen LLMs recognising problem types and attempting to substitute new values into relevant methods, but consistency over long outputs seems to be a real challenge. It may be that attempting to solve more complex problems with just a single LLM pass isn’t the best approach, and some additional structure is required.
For one thing, as discussed above, it may not be possible to avoid LLM memorisation without increasing problem complexity. In which case, it might be better to stick to problems with larger numbers and focus on LLMs that have been trained to use calculation tools.
Multiple LLM model passes could also be beneficial, with extra steps for exploring possibilities, checking solutions and fixing errors.
Lastly, I think if we’re getting to the point were problem synthesis is becoming complex and messy, it might be a good idea to work with our LLMs in a way that helps us and them maintain correctness. If we were working with a formal maths proof checking language, such as Lean, that would make it trivial to explore many interesting directions, such as problem generalisation, solution verification, higher level problem solving, and so on. The challenge for this approach is a lack of relevant data, but that may be something I look into next.