

Issues with MATH()
Issues with MATH()
I have recently been looking at with the MATH() functional dataset, which is a system for synthetically generating math problems and their solutions, to be used as data for evaluating large language models (LLMs). Random values, and derived calculations, are substituted into problem/solution templates. These templates are derived from a static dataset called MATH. Although this generation code has not been released, the evaluation code has, along with three generated datasets (snapshots).
To generate some ground truth data of my own, I solved 100 problems from the test/algebra directory in the December 2023 snapshot of MATH() data. Many of the problems I looked at were tedious or impossible to solve by hand and, in my opinion, unsuitable for evaluating LLMs. I’m going to go these problems in detail in this blog post. These are not cherry picked, I looked through the first 110 problems file by file in order of directory listing.
The problems are written in LaTeX, which I’ve rendered to images when needed (but an LLM would read and generate LaTeX code directly).
Incorrect math
The most serious issue I saw was that for several problems a possible correct answer would be marked as incorrect during evaluation. That means, either the given solution is incorrect, or the question is ambiguous.
Dec-2023/test/algebra/1102.json
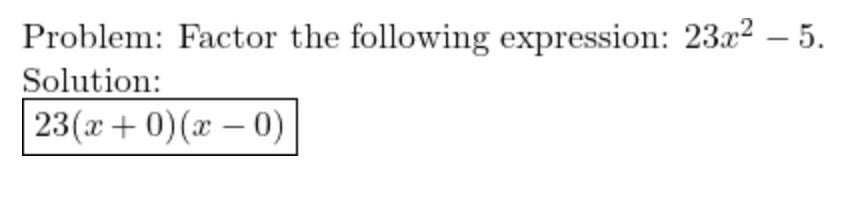
This answer is wrong, it should be 23(x + √(5/23))(x - √(5/23)). I suspect that 5/23 became 0 due to an integer arithmetic rounding error. Probably the question generating code expects to get integers in the answer but there’s a bug in the code for selecting values so this isn’t guaranteed.
Dec-2023/test/algebra/1128.json
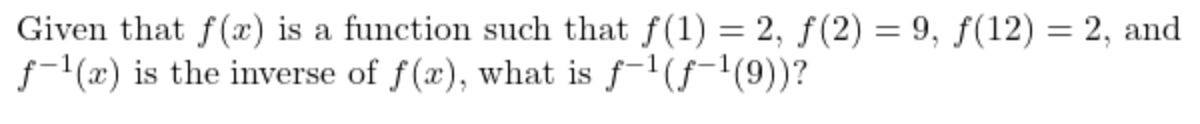
If f(1) = f(12) = 2 then f doesn’t have a well-defined inverse at 2. The given solution is 12, but 1 would be equally valid.
Dec-2023/test/algebra/1195.json

No two consecutive, positive, even numbers match this criteria. Even numbers sum to another even number, so 27 can’t be correct. The prompt for evaluation instructs the model to reply “NO SOLUTION” if a problem has no solution, and that should be the correct response here.
The difference of the squares of 12.5 and 14.5 is 54 and 12.5 + 14.5 = 27. So if the problem specified “two positive numbers with a difference of 2” instead of “two consecutive positive even numbers”, then this would be fine. This suggests the generation code has over-generalised a problem beyond the range where it’s always correct.
Dec-2023/test/algebra/1265.json

The answer to this (trivial) question is 1, which when expressed as a common fraction is 1/1. The given solution 3/3 would not match with either 1 or 1/1, since the provided MATH() evaluation methods use string matching.
Dec-2023/test/algebra/1528.json

I get 97.1*11 / 42 = 10681/420 (which is in lowest terms). This is extremely close but not equal to the given solution here, (both show as 25.430952381 on a calculator), but the evaluation uses string matching methods, and doesn’t compare computed values. So if the model gave a correct solution it would be counted as incorrect. The tiny numerical difference suggests some kind of floating point error. Ideally, the MATH() code would using floats, better to use pairs of integers or a third party library for handling rational numbers.
Dec-2023/test/algebra/1529.json
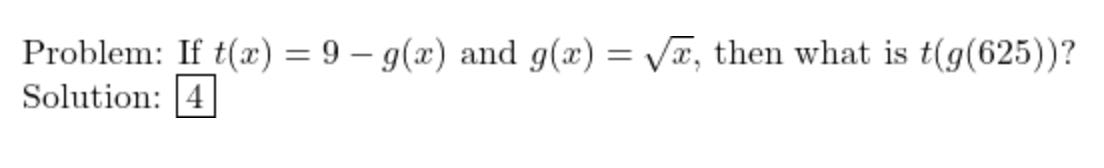
I get g(625) = 25 and t(g(625)) = 9 - 25 = -16. The answer would be correct if g took a fourth root, or if we were computing t(g(25)) or t(g(g(625))). This seems like a bug in the question generation or the solution calculation code.
Dec-2023/test/algebra/1540.json
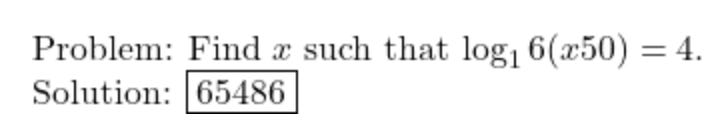
Taking a logarithm base 1 is like dividing by 0, this question is impossible and the response should be “NO SOLUTION”.
In LaTeX the question says log_16. Possibly that should have been log_{16}, meaning logarithm base 16. I don’t think we should expect an LLM to correct for a mistake like this, but even if we did, the answer is still incorrect.
The value of x should be 16*16*16*16/50 = 65536/50 = 1310.72. The solution given is actually 65536-50, which suggests either a bug in the answer calculation, or a missing minus sign.
Dec-2023/test/algebra/1541.json
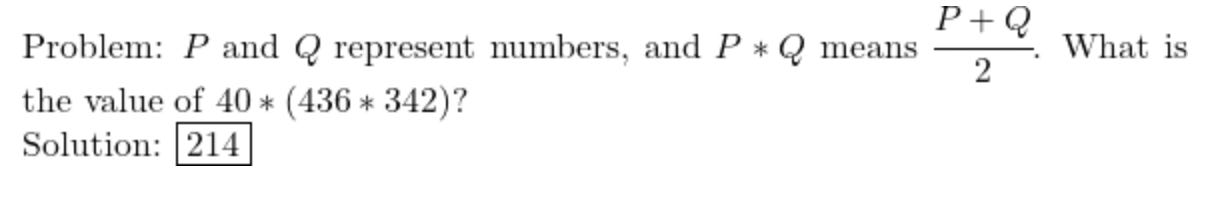
I get (436 + 342)/2 = 389 and (389 + 40)/2 = 214.5, not 214.
The missing half suggests an integer arithmetic rounding error. If the problem was supposed to have an integer solution, then that points to a bug when selecting random values for substitution.
Dec-2023/test/algebra/104.json

The given solution is correct but the question is ambiguous. The answer value is 3640/47, which is not an exact decimal, and there’s no mention of how many decimal places to use. I would guess the original MATH problem had an exact decimal answer, but was generalised too far, without adjusting the question statement accordingly. Since the evaluation uses string matching not approximate value matching, a model response would be counted as incorrect unless it decided to use exactly 14 decimal places. (For reference, I asked GPT3.5-turbo and ChatGPT what 3640/47 is, and they gave me “77.4468085106383” and “77.44680851” respectively, neither of which would be accepted.)
Dec-2023/test/algebra/1044.json, Dec-2023/test/algebra/1490.json and Dec-2023/test/algebra/1514.json
These problems have incorrect solutions due to a LaTeX typo. They all feature a double digit number after a ^ symbol, such as 97^57 (which is rendered as 97 to the power of 5 followed by 7). The given solutions would be correct if we added curly brackets, such as 97^{57} (which now means 97 to the power of 57). This is a common LaTeX mistake, but it’s not clear a language model should be expected to automatically correct for it. It makes these problems harder to solve in a way unrelated to mathematical reasoning, meaning at the very least, it’s a potential source of bias.
Intractable math
The MATH() paper mainly focused on language models without augmented tool use. Most of the models tested were required to solve problems through language generation alone. To get the most relevant data, I wrote out solutions that didn’t require a calculator to follow. However, there were some problems that required unreasonably lengthy solutions or involved very large numbers, which I think makes them unfairly difficult for un-augmented LLMs to generate.
Dec-2023/test/algebra/1023.json
This problem asks for the square root of the sum of the squares of 26360551 and 2498040. I think this kind of problem is meant to be solved by using the equation for the difference of two squares. However, that means checking through possible factor pairs of one of the squares, looking for a pair the right distance apart. In this case, that would mean factorising one of these quite large numbers, followed by searching through over 40 factor pairs. I think this could take at least a hundred calculations to finish.
Dec-2023/test/algebra/1317.json
This requires finding the 41st term in a geometric sequence (which is a sequence that grows exponentially). The answer takes several calculations to derive and ends up being 14 digits long.
Dec-2023/test/algebra/1418.json
This problem requires finding all the points with integer coordinates within a circle of radius 57, centred on the origin. I found the problem in the original MATH dataset that this was generalised from, and the circle radius was 5. I can’t find an easier method for this kind of problem than looking at a quarter of the circle where it intercepts the integer verticals (or horizontals) and rounding down. That’s very tractable to do for radius 5, there are 5 relevant intercepts, and for each you have a calculation that is straightforward if you’re familiar with the first five square numbers. At radius 57 there’s more than ten times as many intercepts, and for each intercept you have the laborious task of finding the integer part of the square root of a four digit number.
Dec-2023/test/algebra/1441.json
This problem asks for the sum of the first 29 powers of 8. The answer is 27 digits long.
Dec-2023/test/algebra/1467.json

Since 343 is 7 cubed, and 16807 is 7 to the power of 5, the left hand side of the equation in this question is 7 to the power of (7n - 3). To solve it, you need the logarithm of the right hand side base 7. This can be done by repeatedly dividing by powers of 7, which is difficult since the right hand side is 7 to the power of 46.
Unpleasant math
Apart from the issues above, many other problems require arithmetic or factorisation with large numbers that I would not expect to find in the original MATH dataset. I think testing out an LLMs ability to consistently do long arithmetic isn’t the same thing as testing if it can reason mathematically, and so comparisons based on this data could be biased.
Dec-2023/test/algebra/1303.json
This problem asks for the difference between the positive square root of 7529536 and the cube root of 7529536. I think the easiest way to solve this is to factorise 7529536, which is 2 to the power of 6 times 7 to the power of 6. That would require a lot of repeated division, and then multiplication to get 2 cubed times 7 cubed, etc.
Dec-2023/test/algebra/1151.json, Dec-2023/test/algebra/143.json and Dec-2023/test/algebra/1438.json
These problems end up involving arithmetic with 8 or more digit numbers.
Dec-2023/test/algebra/109.json, Dec-2023/test/algebra/1169.json and Dec-2023/test/algebra/137.json
These problems involve at least a 6 digit number divided by a 3 digit number. This is quite a long division, which I wouldn’t expect a language model with no calculator augmentation to always do consistently.
Conclusion
I found a surprising number of issues with the MATH() data. Some of those may seem subjective, and my sample size is quite small. However, I think there’s enough evidence here to suggest caution for anyone interpreting results based on this data.